 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverbMiipher: Generative Speech Restoration meets Reverberation Characteristics Controllability
May 08, 2025



Reverberation encodes spatial information regarding the acoustic source environment, yet traditional Speech Restoration (SR) usually completely removes reverberation. We propose ReverbMiipher, an SR model extending parametric resynthesis framework, designed to denoise speech while preserving and enabling control over reverberation. ReverbMiipher incorporates a dedicated ReverbEncoder to extract a reverb feature vector from noisy input. This feature conditions a vocoder to reconstruct the speech signal, removing noise while retaining the original reverberation characteristics. A stochastic zero-vector replacement strategy during training ensures the feature specifically encodes reverberation, disentangling it from other speech attributes. This learned representation facilitates reverberation control via techniques such as interpolation between features, replacement with features from other utterances, or sampling from a latent space. Objective and subjective evaluations confirm ReverbMiipher effectively preserves reverberation, removes other artifacts, and outperforms the conventional two-stage SR and convolving simulated room impulse response approach. We further demonstrate its ability to generate novel reverberation effects through feature manipulation.
Miipher-2: A Universal Speech Restoration Model for Million-Hour Scale Data Restoration
May 07, 2025



Training data cleaning is a new application for generative model-based speech restoration (SR). This paper introduces Miipher-2, an SR model designed for million-hour scale data, for training data cleaning for large-scale generative models like large language models. Key challenges addressed include generalization to unseen languages, operation without explicit conditioning (e.g., text, speaker ID), and computational efficiency. Miipher-2 utilizes a frozen, pre-trained Universal Speech Model (USM), supporting over 300 languages, as a robust, conditioning-free feature extractor. To optimize efficiency and minimize memory, Miipher-2 incorporates parallel adapters for predicting clean USM features from noisy inputs and employs the WaneFit neural vocoder for waveform synthesis. These components were trained on 3,000 hours of multi-lingual, studio-quality recordings with augmented degradations, while USM parameters remained fixed. Experimental results demonstrate Miipher-2's superior or comparable performance to conventional SR models in word-error-rate, speaker similarity, and both objective and subjective sound quality scores across all tested languages. Miipher-2 operates efficiently on consumer-grade accelerators, achieving a real-time factor of 0.0078, enabling the processing of a million-hour speech dataset in approximately three days using only 100 such accelerators.
FLEURS-R: A Restored Multilingual Speech Corpus for Generation Tasks
Aug 12, 2024



This paper introduces FLEURS-R, a speech restoration applied version of the Few-shot Learning Evaluation of Universal Representations of Speech (FLEURS) corpus. FLEURS-R maintains an N-way parallel speech corpus in 102 languages as FLEURS, with improved audio quality and fidelity by applying the speech restoration model Miipher. The aim of FLEURS-R is to advance speech technology in more languages and catalyze research including text-to-speech (TTS) and other speech generation tasks in low-resource languages. Comprehensive evaluations with the restored speech and TTS baseline models trained from the new corpus show that the new corpus obtained significantly improved speech quality while maintaining the semantic contents of the speech. The corpus is publicly released via Hugging Face.
Lenient Evaluation of Japanese Speech Recognition: Modeling Naturally Occurring Spelling Inconsistency
Jun 07, 2023


Word error rate (WER) and character error rate (CER) are standard metrics in Speech Recognition (ASR), but one problem has always been alternative spellings: If one's system transcribes adviser whereas the ground truth has advisor, this will count as an error even though the two spellings really represent the same word. Japanese is notorious for ``lacking orthography'': most words can be spelled in multiple ways, presenting a problem for accurate ASR evaluation. In this paper we propose a new lenient evaluation metric as a more defensible CER measure for Japanese ASR. We create a lattice of plausible respellings of the reference transcription, using a combination of lexical resources, a Japanese text-processing system, and a neural machine translation model for reconstructing kanji from hiragana or katakana. In a manual evaluation, raters rated 95.4% of the proposed spelling variants as plausible. ASR results show that our method, which does not penalize the system for choosing a valid alternate spelling of a word, affords a 2.4%-3.1% absolute reduction in CER depending on the task.
Helpful Neighbors: Leveraging Neighbors in Geographic Feature Pronunciation
Oct 18, 2022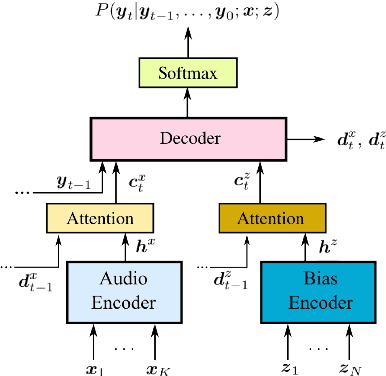

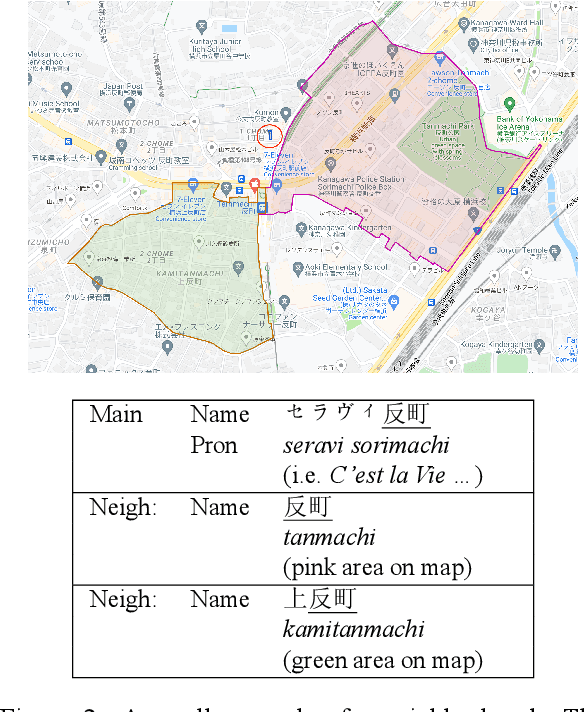
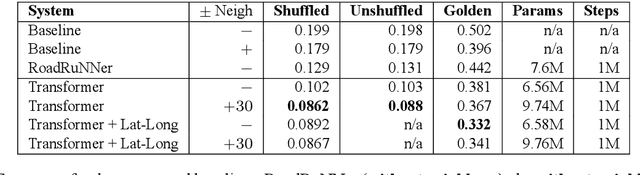
If one sees the place name Houston Mercer Dog Run in New York, how does one know how to pronounce it? Assuming one knows that Houston in New York is pronounced "how-ston" and not like the Texas city, then one can probably guess that "how-ston" is also used in the name of the dog park. We present a novel architecture that learns to use the pronunciations of neighboring names in order to guess the pronunciation of a given target feature. Applied to Japanese place names, we demonstrate the utility of the model to finding and proposing corrections for errors in Google Maps. To demonstrate the utility of this approach to structurally similar problems, we also report on an application to a totally different task: Cognate reflex prediction in comparative historical linguistics. A version of the code has been open-sourced (https://github.com/google-research/google-research/tree/master/cognate_inpaint_neighbors).